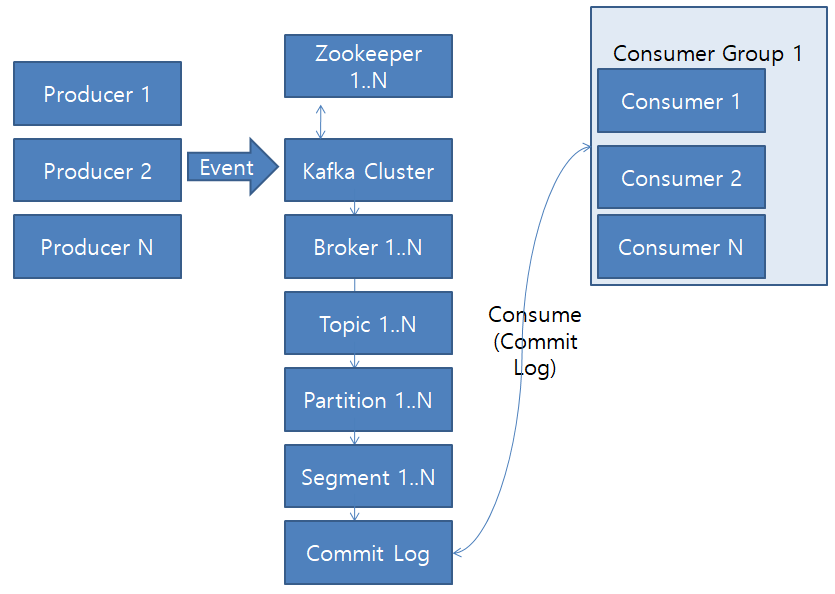
- Broker
- 최소 3대, 권장 4대 이상의 Broker로 Kafka Cluster 구성
- Topic 내의 Partition을 분산, 유지, 관리
- Broker 장애 시? - Broker는 partition을 미리 다른 Broker에 Replication(복제)하여 대비한다. Leader/Follower구조
- Replication Factor 3 ? - Leader 1, Follower 2 (복제2), Follower는 leader에 Fetch Request를 요청하며 commit Log 데이터 요
- Producer와 Consumer는 Broker Leader하고 통신한다.
- Leader 장애 시 Kafka Cluster에서 follower중 Leader선출
- Leader선출 하는 방법? - ISR, In Sync Replicas
- High Water Mark라고 하는 Follower중 Leader의 commit log와 가장 근접하게 복제한 Follower를 Leader선출
- replica.lag.max.messages 5 옵션? : Leader와 Follower가 5개이상 메세지 차이가 나면 지연으로 판단.
- replica.lag.time.max.ms = 1000 옵션? : Follower가 Leader로 Fetch요청 보내는 interval을 체크. 해당 옵션 사용을 권장함.
- 장애 복구된 Broker가 다시 시작할 때 Committed 메시지 목록을 유지하도록 하기 위해, Broker의 모든 Partition에 대한 마지막 Committed Offset은 replication-offset-checkpoint라는 파일에 기록됨
- Broker Controller? - Kafka Cluster중 하나의 Broker가 컨트롤러가된다. 컨트롤러는 Zookeeper를 통해 Broker Liveness 모니터링을 한다.
- Partition Leader가 한 Broker에 집중되지 않도록 하는 옵션
- auto.leader.rebalance.enable : 기본값 enable
- leader.imbalance.check.interval.seconds : 기본값 300 sec
- leader.imbalance.per.broker.percentage : 기본값 10
- Follower는 최대한 Rack 간에 균형을 유지하여 Rack 장애 대비하는 Rack Awareness 기능이 있음 (Rack간 분산)
- n개의 Replica가 있는 경우 n-1개의 장애를 허용할 수 있음
- Follower가 너무 느리면 Leader는 ISR에서 Follower 제거 후 Zookeeper에 ISR을 유지
- replica.lag.time.max.ms 옵션 : 정해진 ms내에 follower가 fetch하지 않으면 ISR에서 제거.
| Follower 장애 | Leader 장애 |
| Leader에 의해 ISR 리스트에서 삭제됨 | Controller는 Follower중 새로운 Leader 선출 |
| Leader는 새로운 ISR을 사용하여 Commit | Controller는 새 Leader와 ISR정보를 zookeeper에 보낸 후 클라이언트 메타데이터 업데이트 정보를 모든 broker에 전달 |
- Zookeeper
- Broker 관리.
- Topic 생성, 제거/ Broker 추가/제거 등의 변경 사항을 Kafka Cluster에 알림
- 최소 3대, 권장 5대의 홀수로 구성. -> ( Quorum(쿼럼). 정족수로 장애 판단 )
- Leader(Writer), Follower(reads)로 구성되어 있다.
- Master/Slave 아키텍처.
- Tree형태로 각 Zookeeper마다 broker들을 맡아 관리, 모니터링
- Consumer Group
- 다른 Consumer Group에 속한 Consumer들은 서로 관련이 없다.
- 하나의 Consumer는 한 Topic의 Partition에서의 Consumer Offset을 별도로 기록하며 Consume함. (ex GroupB:MyTopic:P0:7 / GroupB:MyTopic:P1:3)
- Partition은 항상 Consumer Group내의 하나의 Consumer에 의해서만 사용됨
- Partition이 2 개 이상인 경우? - 모든 메시지에 대한 전체 순서 보장 불가능
- Partition을 1 개로 구성하면? - 모든 메시지에서 전체 순서 보장 가능(처리량 저하)
- partition 4개 <-> Counsumer group A의 Consumer 4개 중 consumer 4번이 장애가 나면 Consumer 1~3번 중 하나에서 추가로 데이터를 consume한다.
- Commit Log
- Commit Log에 있는 Event를 동시에 다른 Consumer가 Read할 수 있음
- Commit Log : 추가만 가능, 변경 불가. 데이터(Event)는 항상 로그 끝에 추가되고 변경되지 않음
- Consumer Lag : Producer가 Write한 LOG-END-OFFSET과 Consumer가 Read하는 CURRENT-OFFSET과의 차이
- Offset
- Offset : Commit Log 에서 Event의 위치. (0번 부터 순차적으로 consume해감.)
- 한 partition에서 Offset값은 계속 증가하고 0으로 돌아가지 않음.
- Segment
- Segment의 default 용량 - 1GB, 시간 - 168 hour
- Segment는 partition당 하나만 Active(write중)
- Page Cache/ Flush
- segment는 OS Page Cahe에 기록됨.(성능을 향상시키기 위해 세그먼트는 OS가 데이터를 디스크에 쓰기 전에 임시로 저장하는 데 사용하는 인메모리 캐시인 OS 페이지 캐시에 기록됨.)
- Zero-copy 전송 : 세그먼트에서 데이터를 읽어 소비자에게 보낼 때 Kafka는 제로 카피 전송을 사용한다. 데이터가 사용자 공간에 복사되지 않고 페이지 캐시에서 네트워크 버퍼로 직접 전송되어 CPU 및 메모리 사용량을 줄이고 처리량을 높임.
- 디스크로 Flush되는 상황(IF ! Flush 되기 전에 broker장애 시? - Replication(follower)가 있음.)
- Broker 완전히 종료될 경우.
- OS background "Flusher Thread" 실행. ( fsync는 기본적으로 비활성화를 권장함. kafka성능을 더 우선시 하기 때문.)
- Partition
- Partition개수는 Topic생성 시 지정한다. (운영중 개수 변경은 권장하지 않음.)
- Topic내의 Partition들은 서로 독립적.
- Partition 에 저장된 데이터(Message)는 변경이 불가능. Immutable
- 동일한 Key를 가진 메시지는 동일한 Partition에만 전달되어 Key 레벨의 순서 보장 가능 (why? - kafka는 key를 hash알고리즘을 사용해 partition을 배정하기 때문. 즉 같은 key면 같은hash가 나오기 때문./ but? - Key 선택이 잘 못되면 작업 부하가 고르지 않을 수 있다)
- 파티션 리더가 있는 Broker 장애 시 리더 선출까지 해당 파티션 사용불가.
- Producer
- Json, String, Avro, Protobuf등의 데이터를 Kafka Cluster에 전달. (Kafka Cluster는 Byte Array(0101010....)형으로 데이터를 받고 Consumer에게 Json, String, Avro, Protobuf 등의 형태로 전달)
- Producer가 Event전달이 잘되었는지 아는 방법?(옵션) - acks, retry
- acks=0 : broker가 producer에 수신완료 신호를 보내지 않음.
- 단점 : 메세지 손실이 있을 수 있다.
- 장점 : 메세지 전송 속도가 빠르다.
- acks=1 : 수신완료 신호 1번
- acks=-1, acks=all : Broker Leader와 Follower 전부 commit되고 신호를 보냄.
- 단점 : 전송 속도 느림, 특정 실패 사례에서 반복수행 할 수 있음
- 장점 : Leader 장애 시에도 데이터 손실 가능성이 낮음
- retry : 오류 시 메세지 전송 재시도 옵션(acks=0 에서는 무의미한 옵션)
-
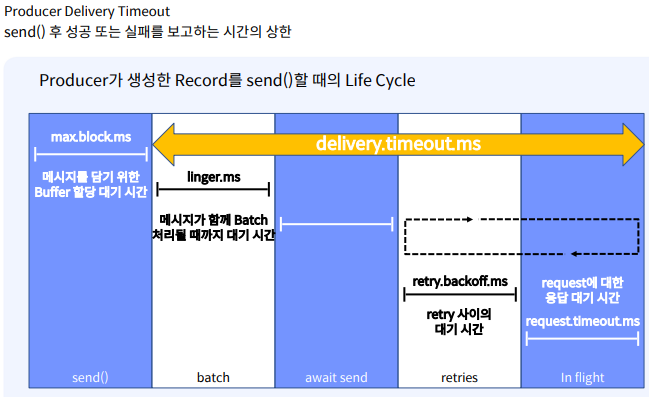
옵션 설명 Default retries 메세지 send 재시도 횟수 MAX_INT retry.backoff.ms 재시도 사이에 추가되는 대기시간 100(0.1초) request.timeout.ms producer가 응답을 기다리는 최대시간 30,000(30초) delivery.timeout.ms 성공/실패의 신호를 보고하는 최대시 120,000(2분)
-
- Producer Batch? : RPC(Remote Procedure Call)수를 줄여 Broker의 처리작업이 줄어 더 나은 처리량 제공.
- linger.ms(default 0) : 메세지 batch처리될 때 까지 대기 시간
- batch.size(default 16KB) : Batch 메세지 최대 크기
- 일반적인 옵션 설정 : lingerms=100, batch.size =1,000,000KB (약 1gb)
- max.in.flight.requests.per.connection=5(default) : 최대 동시 요청 수. 한 번에 최대 5개의 메세지를 동시에 비동기 적으로 전달할 수 있음
- 동시 요청 수가 많을수록 성능은 향상될 수 있지만, 특정 조건에서는 메시지 순서가 꼬일 수 있다.
- 너무 많은 요청 수를 지정할 경우 성능 저하.
- enable.idempotence=true : 재시도에도 메세지 순서를 보장하는 옵션
- 하나의 batch가 실패하면 후속 batch도 OutOfOrderSequenceException에러로 실패함.
- acks=0 : broker가 producer에 수신완료 신호를 보내지 않음.
- Message / Event / Data ....등
- Header, Key, Value로 구성.
'Kafka' 카테고리의 다른 글
| Kafka - __consumer_offsets TOPIC (0) | 2024.06.07 |
|---|---|
| Kafka 실행 (0) | 2024.06.07 |
| Kafka 설치 (1) | 2024.06.07 |
| Kafka - Apache Kafka and Confluent Reference Architecture (0) | 2024.06.05 |
| Kafka - Exactly Once Semantics(EOS) 2 (0) | 2024.06.04 |