Hive와 Impala모두 Sql On Hadoop으로 하둡에 저장되어 있는 데이터를 sql를 활용하여 데이터를 분석할 수 있다.
●Hive => 변하지 않는 데이터의 매우 큰 데이터 집합에 대한 배치처리에 적합
- Hadoop에 저장된 메타 데이터를 Table Schema 정보와 함께 메타스터오에 등록하여 RDBMS에서와 같이 SQL을 활용하여 사용할 수 있다.
- 기존 hadoop의 map-reduce를 활용해 사용하던 방식을 SQL문을 활용 할 수 있도록 facebook에서 개발 후 오픈소스화 함.
- Map-Reduce의 모든 기능 지원
- Hive Query -> Map-Reduce로 변환되어 실행됨.
- Query 파싱, 실행계획 수립, 최적화 과정을 거쳐 map-reduce로 변환하여 처리하므로 응답시간이 긴 편인다.
- 대량의 데이터 full-Scan에 최적화.
- Map-Reduce 사용시 다수의 사용자 요청을 동시에 처리하는데는 한계가 있다.
- 대화형의 Onlene Query사용엔 부적합. 배치처리 기반의 Map-Reduce를 통해 처리하므로
애드혹(ad-hoc) Query를 실행하거나, BI/시각화 도구, 어플리케이션에서의 대화형 방식의 분석은 실행속도↓
- 전체 정렬을 단순 Hive QL로 실행 시 하나의 Reduce만 실행되어 성능 저하
- 데이터의 부분적인 수정/삭제 (update, delete가 불가) -> partition으로 분리하여 해당 파티션을 지우고 새로 적재하는 방법을 권장, 0.14ver부터는 부분적 지원
- 트랜잭션 관리 기능이 없어 롤백 처리 불가 -> 하나의 hive쿼리는 여러 개의 job과 map-reduce프로그램으로 실행되며, 로컬 디스크에 중간 파일들을 만들어낸다. 이때 특정 reduce작업 하나가 실패하면 이미 성공한 job들이 롤백 처리 되지 않으며 실패한 job을 재실행 한다. 0.14ver부터 부분적 지원이 되지만 제약사항이 많다.
- Hdfs, HBase(컬럼기반 데이터 베이스), Accumulo(정렬된 분산 컬럼기반 저장소), Druid(BI/OLAP전용 분석데이터 저장소), Kudu(빠른 컬럼기반 저장소) 등 다양한 저장소에서 Hive사용 가능.
● Hive 아키텍처

- Hive는 UI, Driver, Compiler, Metastore, Execution Engine으로 구성
- UI : 사용자가 시스템에 쿼리 및 기타 작업 요청하기 위한 인터페이스 CLI, WEB GUI가 있다.
- Driver : JDBC/ODBC 인터페이스를 통해 세션을 생성하여 쿼리 실행
- Compiler : 쿼리 구문 분석, 메타스토어의 Table 및 Partition정보를 활용하여 실행플랜 생성
- Metastore : 데이터 저장소 HDFS 정보 포함, Table, Partition, Column, Column type 등의 구조정보 저장
- Execution Engine : Compiler 생성한 실행플랜 실행
● Hive 데이터 모델
Table
Partition
bucket : table의 column 해시를 기반으로 데이터를 지정된 개수의 파일로 분리해서 저장
각 버킷은 partition 디렉토리에 파일로 저장.
데이터 조회 및 Join시 필요한 버킷의 파일만 사용하여 쿼리 성능 향상 가능.
● Impala =>
- Hive가 가지고 있는 실시간성 Query 성능 문제와 멀티 사용자 지원을 해결하기 위해 탄생
- hadoop용 인터랙티브 SQL, 빠른 응답을 위한 분석 또는 ad-hoc Query에 최적화
- 자체 분산 Query Engine을 사용하여 응답속도가 빠르다.
- 단일 명령문에 대한 트랜잭션은 지원하나 다중 명령문에 대한 트랜잭션은 지원하지 않는다.
- 전용 메타스토어 사용할 필요 없이 기존 hive 메타스토어를 사용.
- 데이터의 부분적인 수정/삭제 (update, delete가 불가)
● Impala 아키텍처(주황색), Hadoop 컴포넌트(파란색)
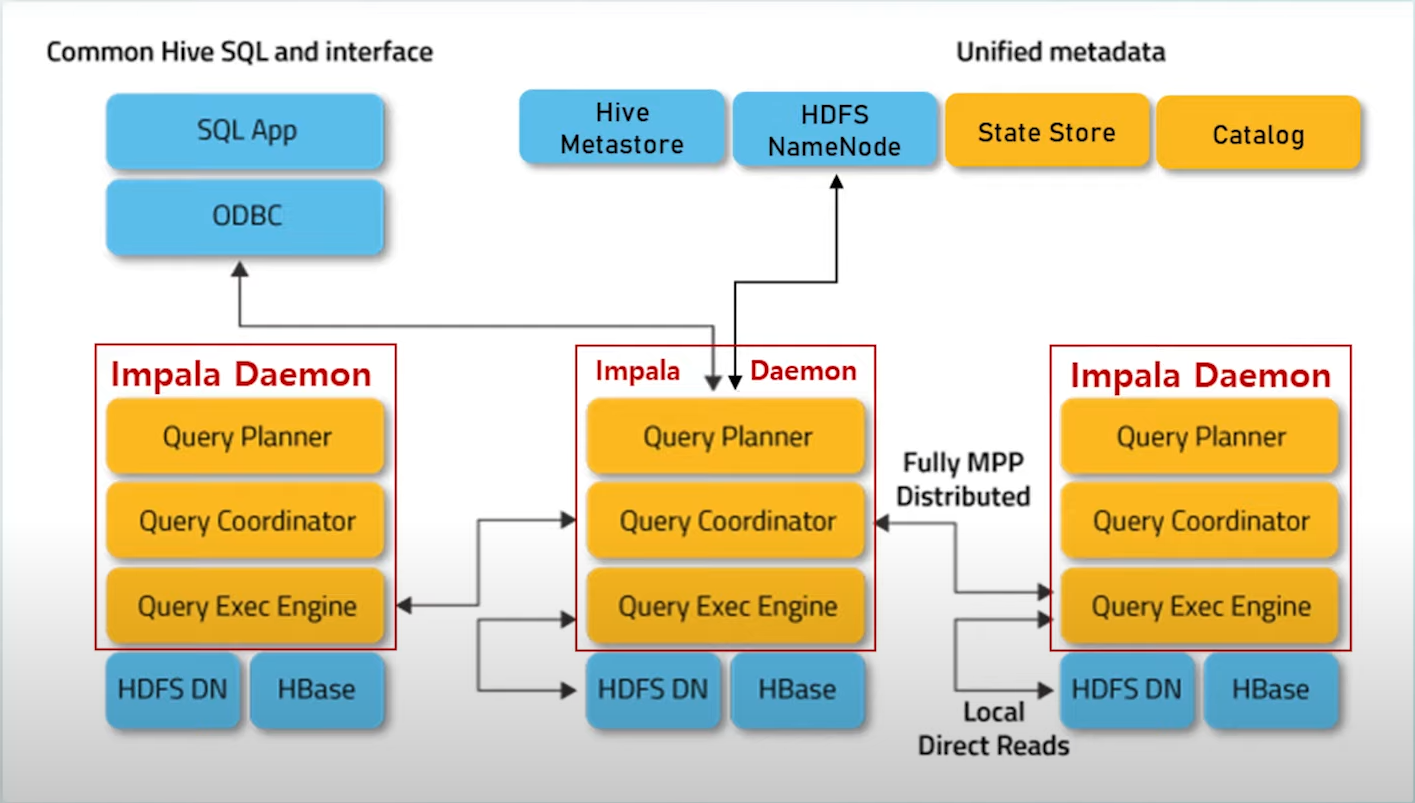
- Impala Daemon(Impalad) : Hadoop Data Node에서 실행되는 Impala 프로세스이다. 사용자 쿼리를 요청받아 Query Planner, Coordinator, Executor 역할을 수행 데이터 파일 Read/Write기능 수행
- Impala Statestore(Statestored) : Cluster에 있는 모든 impala Daemon의 상태를 확인하고 그 결과를 각 Daemon에 지속적으로 전달, Catalog Service에서 요청받은 메타 데이터 동기화 작업에 대한 브로드캐스팅 역할을 수행
- Impala CatalogService(catalogd) : impala sql문에서 cluster의 모든 impala Daemon으로 메타데이터 변경 사항 전달. impala Daemon에서 직접 메타데이터 변경 시 자동 동기화. hive나 hdfs에서 변경 시 Refresh문으로 동기화 작업 수행해야 한다.
● Impala 데이터 모델
Database
Table
View
Function
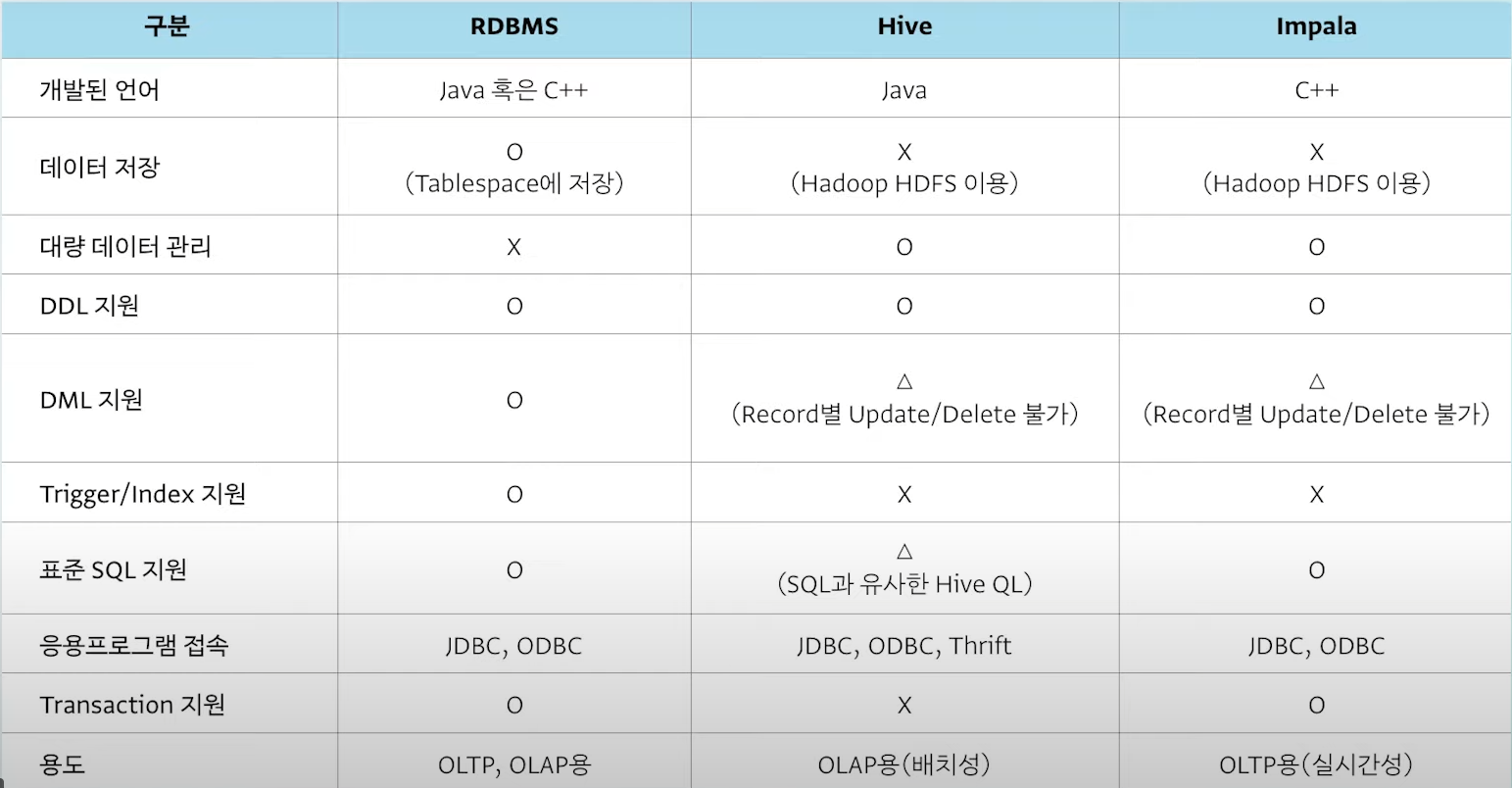
● Rdms, Hive, Impala 비교
※ Adhoc쿼리 : 코드가 실행될때마다 변경되는 쿼리를 말한다.
ex) var newSqlQuery = "SELECT * FROM table WHERE id = " + myId;
위 코드를 보면 myId 의 값에 따라서 쿼리문이 변경됨을 알 수 있다.
'Hadoop' 카테고리의 다른 글
| Hadoop - HDFS 페더레이션 (1) | 2024.07.04 |
|---|---|
| Hadoop - 다수의 작은 파일 vs 하나의 큰 파일 (2) | 2024.07.04 |
| Hadoop - HDFS, 네임노드, 데이터 노드, NFS (0) | 2024.05.21 |
| Hadoop eco system (3) | 2024.05.13 |
| hdfs 휴지통 (1) | 2024.04.11 |