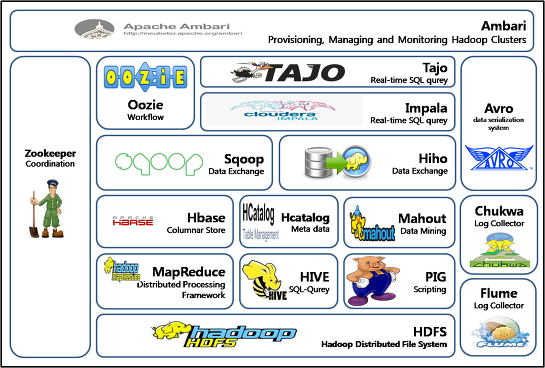
Spark란 빅데이터 처리를 위한 오픈소스 분산 처리 플랫폼이다. 하둡과의 차이점?하둡은 HDFS(분산형 파일 시스템)를 기반으로 만들어져있고, 데이터 처리시 '맵리듀스'라 불리는 대형 데이터셋 병렬 처리 방식에 의해 작동한다.HDFS는 Disk I/O를 기반으로 동작. 스파크는 인메모리상에서 동작한다.메모리 이슈만 없다면반복적인 처리, 배치성 데이터, 실시간 스트리밍 처리 등에서 속도가 훨씬 빠르다. 하둡과 스파크를 연동하여 처리하는게 가능한데,하둡의 Yarn(하둡 클러스터의 리소스(cpu,mem)를 관리하고 작업을 스케줄링하는 역할)위에스파크를 연동하여 구축하는 방법이 일반적이다. 스파크에서 사용하는 언어?일반적으로 Scala, Java, Python 사용하며 다양한 언어를 지원한다.SQL은 Spar..