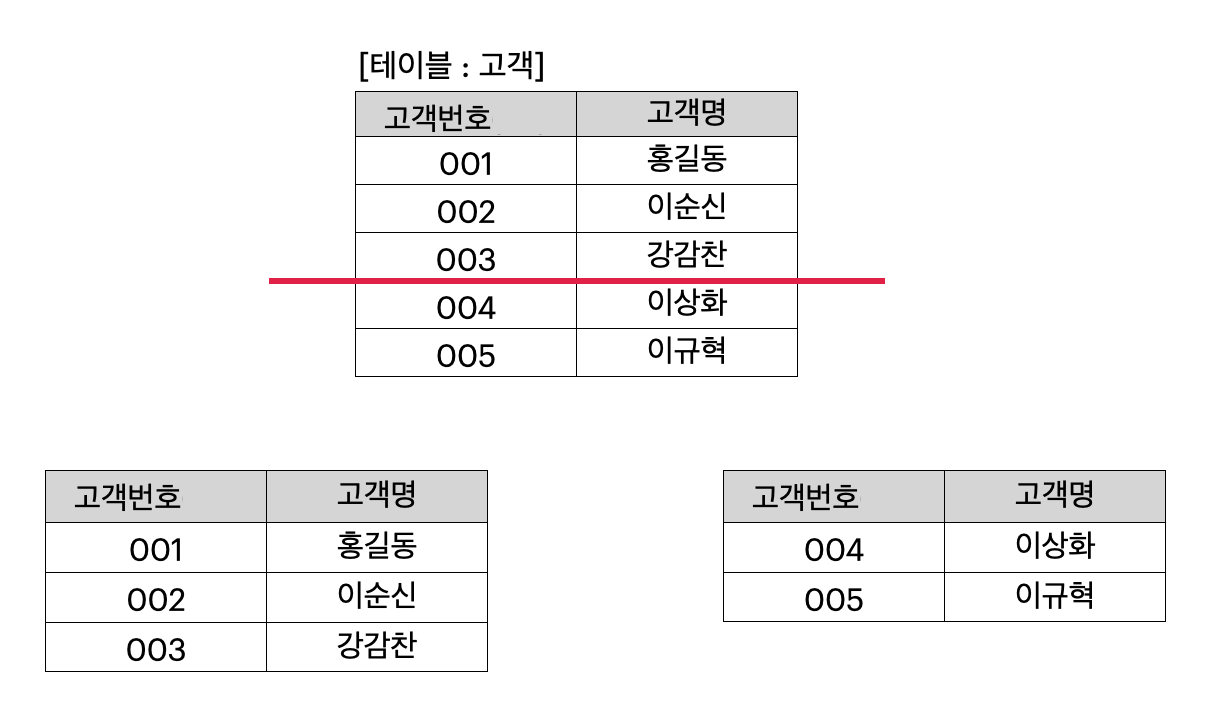
DB - partition 수평/수직 분할
데이터베이스 분할(Partitioning)? 데이터베이스 분할은 데이터를 여러 개의 작은 조각으로 나누는 작업으로 이렇게 분할된 데이터들은 데이터 관리 용이성, 성능, 가용성 등의 향상을 위해 사용되며 분할된 각 부분을 '파티션'이라고 부른다. 분할기법 종류 수평 분할 (Horizontal Partitioning)수평 분할은 데이터베이스의 테이블을 행(Row) 단위로 나누는 것을 의미한다.예를 들어, 가상의 "고객 정보"라는 테이블에 각 고객의 이름, 나이, 주소, 이메일 등이 저장되어 있고, 이 "고객 정보" 테이블을 수평 분할하려고 하는 경우지역별로 분할: 고객 정보를 한 지역에 사는 고객들과 다른 지역에 사는 고객들로 나눈다. 예를 들어, 한 테이블은 미국 고객의 정보만을 포함하고, 다른 테이블은..